Hello World.
Tailscale-Traefik integration
Originally posted on the traefik blog on January 2023.
Last month, we announced the release of the first beta for Traefik Proxy 3, and with it came the exciting new integration with Tailscale, a VPN service that allows you to create your own private networks from your home, using whatever device you want.
But Tailscale goes beyond providing a service to create a private network. It also offers TLS certificate management, where Tailscale provides you with a valid certificate for your internal Tailscale services. Behind the scenes, Tailscale gets the certificate from Let’s Encrypt. The biggest benefit here is that Tailscale manages the certificate lifecycle for you, so there is no need to worry about renewing or exposing an endpoint to resolve TLS challenges between Let’s Encrypt and your proxy instance.
In this article, I want to show you the two main ways Traefik Proxy makes use of Tailscale — one based on the utilization of the TLS management feature, and one bonus story for nerds! You can also check out the announcement of the Tailscale-Traefik integration on the Tailscale Blog.
Tailscale as a TLS certificates provider
Tailscale is, first and foremost, a VPN, which means all traffic between the nodes of your tailnet is already encrypted by WireGuard. If you're running, for example, a webserver on one of your nodes (i.e. your server), and you want to reach it from another of your nodes (i.e. your laptop), there is no need for HTTPS, in terms of security, and you could do it over HTTP.
However, software at the application level (e.g. your browser) is unaware that traffic is already encrypted, and it might, rightfully so, "complain" about it — your browser will display the Not secure warning near the URL bar. Other tools might even be stricter about it.
For this reason, Tailscale also offers a (beta) feature for HTTPS certificates, which provides you with a Let's Encrypt TLS certificate for the nodes in your tailnet.
Once this feature is enabled, instead of your laptop reaching your server with http://your-server-tailscale-IP, you can reach it with https://your-server-tailnet-name — assuming your server can do HTTPS as well — making your browser happy, as it sees you are using TLS, and your life easier.
If you are interested in trying this feature without Traefik Proxy, you need to follow the steps below:
- Set up the Tailscale bits
- Set up your webserver (or reverse proxy) to handle TLS
- Call
tailscale certon your server to ask Tailscale to provide you with the TLS certificate - Adjust your webserver configuration to take that certificate into account
- Handle certificate renewal later on
Automating TLS certificates with the Traefik-Tailscale integration
Now, if you want to try this Tailscale feature with Traefik Proxy, you have a way of automating this process. Traefik comes with an ACME provider, which can be configured to automatically ask Let's Encrypt for certificates, for the relevant routes described on its configured routers.
In that respect, Tailscale's role as a certificate provider is very similar to Let'sEncrypt, so it made sense for us to capitalize on the experience we already had with the ACME provider, and adapt the work to add the same feature for Tailscale.
Let's showcase the feature with an example of a setup from A to Z.
- Start with the Tailscale part: In your tailnet’s DNS settings, enable
MagicDNS, make a note of your tailnet name for later (in the example below, you'll have to replaceyak-bebop.ts.netwith your own), and enableHTTPS Certificates. - Configure Traefik Proxy: We'll use the file provider for simplicity, but there are examples for the other providers on our documentation page that you can easily adapt for this example. Static configuration:
- Start Traefik Proxy: On startup, Traefik should automatically try to get certificates for TLS routes with a
Hostrule, which, in our example, means that, if everything goes well, you should see log lines (if your log level isDEBUG) such as:
[entryPoints]
[entryPoints.websecure]
address = ":443"
[providers]
[providers.file]
filename = "/path/to/your/dynamic.toml"
[certificatesResolvers.myresolver.tailscale]
[api]
debug = true
[log]
level = "DEBUG"
Dynamic configuration:
[http]
[http.routers]
[http.routers.towhoami]
service = "whoami"
rule = "Host(`myserver.yak-bebop.ts.net`)"
[http.routers.towhoami.tls]
certResolver = "myresolver"
[http.services]
[http.services.whoami]
[http.services.whoami.loadBalancer]
[[http.services.whoami.loadBalancer.servers]]
# docker run -d -p 6060:80 traefik/whoami
url = "http://localhost:6060"
Note: In the Host rule, we're using our full Tailscale hostname for the server — the concatenation of the server's machine name, myserver, (that you can find in your Tailscale admin console, or with the tailscale status command), and the tailnet name, yak-bebop.ts.net, that is provided with MagicDNS.
2023-01-09T11:02:51+01:00 DBG ../../pkg/server/router/tcp/manager.go:235 > Adding route for myserver.yak-bebop.ts.net with TLS options default entryPointName=websecure
2023-01-09T11:03:36+01:00 DBG ../../pkg/provider/tailscale/provider.go:253 > Fetched certificate for domain "myserver.yak-bebop.ts.net" providerName=myresolver.tailscale
2023-01-09T11:03:36+01:00 DBG ../../pkg/server/configurationwatcher.go:226 > Configuration received config={"http":{},"tcp":{},"tls":{},"udp":{}} providerName=myresolver.tailscale
2023-01-09T11:03:36+01:00 DBG ../../pkg/tls/certificate.go:158 > Adding certificate for domain(s) myserver.yak-bebop.ts.net
Enjoy your TLS route! You can now access your Tailscale hostname (https://myserver.yak-bebop.ts.net in the example) over HTTPS in your browser
Tailscale as a tunnel between a Mac host and containers
The (convoluted) background
The Traefik project, just like most large software projects, has integration test suites that we run both on our development machines (mostly laptops), and automatically on our Continuous Integration (CI) platform when submitting a pull request, notably to detect regressions.
In our case, that usually means we use at least three components for a test: Traefik itself, a third-party component, like a backend (e.g. the traefik/whoami webserver), and the test itself, which can be mainly viewed as an (HTTP, or not) client that makes requests in Go.
For historic reasons, at some point, we ended up in a situation where all of these components would, by default, run in Docker. The rationale is the usual: you want reproducibility so that the setup is the same everywhere, and the test will run on the CI, as well as your laptop. And on your dev laptop, it also allows you to avoid the need to install and configure various third parties — think databases, for example.
However, on Mac machines, there are two (sort of interlinked) major drawbacks to that situation: slow run time, and inconvenient workflow.
When we are debugging, or working on a new feature, it is pretty important to be able to make a change, rerun one test in particular, and get some feedback in a decent amount of time. Otherwise, aside from being tedious, you're stuck in this in-between where there's not enough time to context-switch to something else, and it's not fast enough to stay in the ideal flow where you can keep on iterating.
Having Traefik Proxy in Docker is an obstacle for two reasons. First, the Docker image has to be rebuilt for every little iteration you want to try, which is automated but is still somewhat slow. Second, it means the whole test setup and run is also way slower than it should be, especially on Mac, mostly because there's a Linux VM in between.
As the vast majority of the Traefik team is using Mac now, this had become an annoying enough problem that we wanted to take care of it. And that is when one of us nerd-sniped another into using Tailscale. Why, you ask? Because of the aforementioned Linux VM.
See, the best of both worlds would be to keep the third-party backends in Docker (for convenience), but take Traefik and the client code out of Docker. This means the clients, and Traefik, have to be able to reach the backends in their containers (and sometimes vice-versa). On Linux, it is somewhat doable, but on Mac, it gets considerably harder, given that there is a Linux VM in between the Mac host and the containers. So, we wanted to see if Tailscale allowed us to achieve that with minimal work.
The solution
The basic idea that is key to the solution is another nifty Tailscale feature, the subnet router. If a Tailscale node sits in a container that is in the same Docker network as all our other Docker containers, then it can reach all these containers. And since it is also part of our tailnet, it can also reach our Mac host (assuming that this host is also part of the tailnet, of course), acting as a gateway between both networks. For the more technically inclined, most of the changes related to that idea are in this commit.
The gist of it is that now we have a flag (IN_DOCKER environment variable) which conveys the intent whether to build Traefik Proxy and to run the tests in Docker or directly on the host.
If not true, we look for a tailscale.secret file, which should contain a Tailscale auth key (ephemeral, but reusable). We then start, with the docker compose API, a tailscale/tailscale container in the same Docker network as the other containers, in which we run Tailscale with the auth key, and --advertise-routes=172.31.42.0/24, in order to make it a subnet router for all the Docker containers.
Finally, for the gritty details on the Tailscale side, I want to mention two things:
- As seen above, you need to generate an ephemeral, reusable
auth key, which can be done on your Keys page at https://login.tailscale.com/admin/settings/keys - You need an
autoApproverssection in the ACLs, in order to automatically approve the routes to the subnet relay. For our purposes, it looks like this:
"autoApprovers": {
// Allow myself to automatically advertize routes for docker networks
"routes": {
"172.0.0.0/8": ["your_tailscale_identity"],
},
},
And that's pretty much it!
So even if the idea of using a VPN to communicate between your host and some containers in Docker seems like overkill, it actually works! And it does make our life simpler as it considerably improves the feedback loop for us when iterating on tests.
Is there a better solution? Probably.
Would it require considerably more changes to our tests setup? Maybe.
Was it fun to do? Definitely ;-)
Don’t forget to check out the announcement of the Tailscale-Traefik Proxy integration on the Tailscale Blog and their official documentation
Le corbeau et le renard
Ворона и Лиса.
На ветви, там была ворона.
Она держала клювом сыр.
Лиса понюхала сыр, и сказала:
"Здарова ворона.
Ты очень красивая.
Если твой голос красивый как твои перья,
ты наверно прекрасно поёшь."
Ворона хотела показать её красивый голос,
и так она открыла её клюв чтобы пропеть,
и так сыр упал.
Лиса взяла сыр, и сказала:
"Сыр мой приз, потому что я преподала тебе урок:
ты не должна слушать льстеца".
A tale of dependencies
TL;DR: Suppose your end-product already depends on many libs, including your own pkg A, and third-party pkg B. Then letting a change to A in, that then makes it depend on B too, can have serious, sneaky, and interesting consequences.
Copy of the commit message for this Camlistore commit:
pkg/osutil: remove dependency on pkg/env
pkg/osutil started depending on pkg/env in
c55c860 , when we added
DefaultLetsEncryptCache(), because it behaves differently whether we're
on GCE or not.
This in turn made pkg/osutil depend on
cloud.google.com/go/compute/metadata and a couple of others. This, in
itself, was not so bad since the main user of pkg/osutil,
server/camlistored already depends on all these same dependencies
anyway.
However, pkg/types/camtypes depends on pkg/osutil (although maybe it
shouldn't) because it calls osutil.UserClientConfigPath() for an error
message.
And finally, in app/publisher/js - which is some Go code meant as input
for gopherjs, so that it gets compiled into javascript that we include
in the publisher web page - we depend on pkg/types/camtypes for some
search query results.
So as of c55c860, we "leaked" a couple
of additional and unnecessary dependencies into the gopherjs generated
code. That made the minified output unnoticeably grow, and apparently
had no other adverse effect, so we didn't notice.
That is, until we landed b0b6a0a, which
updated a ton of vendored dependencies, most of them in
cloud.google.com/go and google.golang.org/api. And interestingly, the
update made cloud.google.com/go/compute/metadata depend on a lot of
these other dependencies. This had two noticeable consequences:
1) The (unminified) generated js code grew from 6.1M to 8.2M, which in
itself is super bad already.
2) The js code actually stopped working. For some reason (that I can't
explain, and will probably leave to the GopherJS devs if they're
interested), the members/functions that we export to the javascript
namespace with gopherjs (typically with a
js.Global.Set("ExportedNameForFoo", FooFunc)), are not visible anymore,
which of course breaks everything.
Therefore, this CL fixes this issue by simply doing what we knew we
should have done from the start:
we now let pkg/osutil/gce (which already depends on pkg/env) itself
register a LetsEncryptCacheFunc into pkg/osutil, which removes the need
for pkg/osutil to depend on pkg/env.
Google Music VS Free.fr
When I bought the Nexus 5X, I got a 3 months free trial of Google Music with it. Last may I finally decided to give it a try. Below is the data I collected about this trial. I explain in the following what they mean.
| Date | Satisfaction | Time of failure |
|---|---|---|
| 2016-05-08 | -2 | |
| 2016-05-09 | 2 | |
| 2016-05-10 | -1 | 18:00 |
| 2016-05-11 | -2 | 18:45 |
| 2016-05-12 | 2 | |
| 2016-05-13 | 2 | |
| 2016-05-14 | 1 | |
| 2016-05-15 | 0 | |
| 2016-05-16 | 2 | |
| 2016-05-17 | 2 | |
| 2016-05-18 | -2 | 19:20 |
| 2016-05-19 | 1 | |
| 2016-05-20 | 2 | |
| 2016-05-21 | 2 | |
| 2016-05-22 | -1 | |
| 2016-05-23 | 2 | |
| 2016-05-24 | 2 | |
| 2016-05-25 | -2 | 21:00 |
| 2016-05-26 | 0 | |
| 2016-05-27 | 0 | |
| 2016-05-28 | 0 | |
| 2016-05-29 | 0 | |
| 2016-05-30 | -1 | 18:30 |
| 2016-05-31 | 1 | |
| 2016-06-1 | -2 | 20:30 |
| 2016-06-2 | 1 | |
| 2016-06-3 | -2 | 18:45 |
| 2016-06-4 | 1 | |
| 2016-06-5 | 2 | |
| 2016-06-6 | 2 | |
| 2016-06-7 | 1 | |
| 2016-06-8 | 2 | |
| 2016-06-9 | 1 | |
| 2016-06-10 | 2 | |
| 2016-06-11 | 1 | |
| 2016-06-12 | 2 | |
| 2016-06-13 | -1 | 18:45 |
| 2016-06-14 | 1 | |
| 2016-06-15 | -2 | 19:30 |
| 2016-06-16 | -2 | 18:00 |
| 2016-06-17 | -2 | 18:00 |
| 2016-06-18 | 2 | |
| 2016-06-19 | 2 | |
| 2016-06-20 | 2 | |
| 2016-06-21 | 1 | |
| 2016-06-22 | 2 | |
| 2016-06-23 | 1 | |
| 2016-06-24 | 2 | |
| 2016-06-25 | 2 | |
| 2016-06-26 | 2 | |
| 2016-06-27 | -2 | 17:30 |
| 2016-06-28 | -2 | 17:49 |
| 2016-06-29 | 2 | |
| 2016-06-30 | 1 | |
| 2016-07-1 | 0 | |
| 2016-07-2 | 0 | |
| 2016-07-3 | 0 | |
| 2016-07-4 | 2 | |
| 2016-07-5 | 1 | |
| 2016-07-6 | 2 | |
| 2016-07-7 | 1 | |
| 2016-07-8 | 0 | |
| 2016-07-9 | 0 | |
| 2016-07-10 | 0 | |
| 2016-07-11 | 0 | |
| 2016-07-12 | 1 | |
| 2016-07-13 | 1 | |
| 2016-07-14 | 2 | |
| 2016-07-15 | 2 | |
| 2016-07-16 | 1 | |
| 2016-07-17 | 0 | |
| 2016-07-18 | 2 | |
| 2016-07-19 | 1 | |
| 2016-07-20 | 2 | |
| 2016-07-21 | 1 | |
| 2016-07-22 | 2 | |
| 2016-07-23 | -2 | 18:20 |
| 2016-07-24 | 2 | |
| 2016-07-25 | 2 | |
| 2016-07-26 | 2 | |
| 2016-07-27 | 1 | |
| 2016-07-28 | 2 | |
| 2016-07-29 | 1 | |
| 2016-07-30 | 2 | |
| 2016-07-31 | 0 | |
| 2016-08-1 | 2 | |
| 2016-08-2 | 2 | |
| 2016-08-3 | 1 | |
| 2016-08-4 | 2 | |
| 2016-08-5 | 1 |
The reason I started collecting this data was because I noticed how prone to interruptions the service was. A track would stop playing because buffering it wasn't fast enough and playing would catch up with it. When things got at their worst, this would happen several times during a track, like every minute or even every 30 seconds or so. The satisfaction reflects my (subjective) patience with the issue (which was pretty low), according to the following ranking:
- 2: No issue to report on that day.
- 1: Very few interruptions.
- 0: No data on that day.
- -1: Enough interruptions to annoy me.
- -2: Enough interruptions to infuriate me and quit using the service on that day.
To give some perspective, I would give it a -2 if several tracks in a row were interrupted several times.
Now as you can see, most of the failures would happen in the evening, which is probably peak time for internet connections at home. Or at least the first burst, compared to the rest of the day, where people are at work, and not using their home connections. So I would not be surprised if the blame was at least in part on my ISP (Free.fr), and not just on Google Music performance. Especially in the light of the history of conflicts between Google (well, youtube) and Free.fr.
Still, I felt that Google Music had some means to alleviate the problem, such as degrading the quality of the audio stream on the fly when bandwidth would get too low. Or even better, give the user some control over how much of the track should be cached before starting to play it. I can stand getting a lower quality music, or having to wait a bit before a track starts, as both these inconveniences are way less annoying than a track getting interrupted right in the middle of it.
I mentioned all of that when I reported the issue to Google Music, which I did pretty early on. And to be honest, I had my mind set on not renewing the subscription when the free trial expired, if the situation did not improve. It is also why I collected the data, so I could explain and justify at the end of the trial, and maybe run some stats on it.
However, much to my surprise, the situation did improve over July, and it's been pretty much at the same quality level since then. And so I don't really have any reason to analyze the data furthermore, but here it is in case someone else is interested. And I therefore did keep the (paying) service.
I don't know if the Google Music peeps did do something (since one does not get any feedback on reported issues), or if somehow Free.fr picked up on the bottlenecks (for me or in general) at the evening hours and improve on it. But whoever it is, I'm grateful about it.
My precious thoughts on Go
Apparently there is a tacit rule on the internet that you have to write a blog post about Go as soon as you have run your first Hello World. I am unfortunately a tad late to the party, but here it is.
I like it. A lot.
And it is called Go.
Thank you for your much desired and totally undeserved attention.
A tale of two screens
Or, a silly xrandr trick.
I use my laptop as my daily work machine, so it is often plugged to an external screen. And, the linux desktop being what it is (Yay, projectors!), it does not work flawlessly to switch between the two displays. Hence this little script I've been using for a while:
#!/home/mpl/plan9/bin/rc
if (! ~ $1 big small) {
echo 'Usage: scr big|small'
exit
}
switch ($1){
case big
xrandr --output HDMI1 --auto
wait
xrandr --output LVDS1 --off
case small
xrandr --output LVDS1 --auto
wait
xrandr --output HDMI1 --off
}
exit 0
However, it has the unfortunate consequence of completely wrecking any pretense of automatic display detection left.
So it's friday night, the HDMI display was the one activated, and I close the laptop lid to make it sleep. The next day, I unplug everything and take the laptop to the couch for some relaxing saturday hacking. And of course, when I wake it up I get a black screen, because I forgot to switch to the LVDS before unplugging the external monitor.
Now one's first reflex is to switch to the vt1 console to try and fix things from there, right? Let's see:
% xrandr --output LVDS1 --auto Can't open display
Of course, forgot to set the DISPLAY, silly me.
% DISPLAY=:0.0 xrandr --output LVDS1 --auto
Back to vt7: still all black. What could be going on? Let's run it in an xterm then:
% DISPLAY=:0.0 xterm -e /bin/bash -c "xrandr --output LVDS1 --auto"
Same result. Now that's about where I had given up a while ago, and I had been resorting to that until now:
Switch to vt7, unlock xscreensaver by typing your password blindly, then back to vt1:
% DISPLAY=:0.0 xterm
Back to vt7, hope the focus is on the newly created xterm, and run blindly my script:
% scr small
which would usually work, but was still too fiddly for my taste.
Today I finally got annoyed enough to debug the issue further (with the LVDS display on, to see what was happening):
From vt1:
% DISPLAY=:0.0 xterm -e /bin/bash -c "/home/mpl/bin/scr small; sleep 60" # sleep for a while so the term does not close immediately after.
On vt7, observe in xterm:
xrandr: Configure crtc 0 failed
Could it be that xrandr is sad because we're not on vt7 when the command is run? (spoiler: yes). So here's for the final silly trick:
% DISPLAY=:0.0 xterm -e /bin/bash -c "sleep 5; /home/mpl/bin/scr small; sleep 60" # give ourselves 5 seconds to switch to vt7.
That gives me a few seconds to switch to vt7, before the command is actually run, which does the trick. Stupid, but it works.
Why containers are the shit
As of today (2014/12/16), you have probably all heard of the containers rage, and about docker in particular.
In the Camlistore project, we have been using docker for a while, and I have come to appreciate why it is useful and convenient. A couple of notable examples are:
-
unit tests: say we want to test all of our indexer implementations (cznic/kv, mongo, mysql, postgres, etc.). But if like myself your dev machine is your laptop, you might not want to have all of the required backends installed on your machine. Or you are too lazy to configure them all properly. Or you do not want them constantly running on your laptop because it eats up juice and you do not want to have to remember to shut them down when you are travelling.
So instead for each backend we just automatically fire up a docker container off the relevant image, run our test(s) against it, and kill the container. Pretty easy to find existing docker images for mysql and such, and if not, it would not be much harder to bake our own anyway.
-
easy deployment: we have been working towards making it easier to deploy Camlistore on a variety of platforms. There are lots of ways to approach this, but running CoreOS (which uses docker as its "packages manager") on Google Compute Engine is definitely an interesting one. All it takes is:
- a CoreOS image: just pick one.
- a CoreOS cloud configuration: not very complicated, with the online doc.
- the docker images you want to deploy. In our case, one for mysql, and one for Camlistore (camlistore/camlistored) that we built ourselves.
Here's the thing though: most of these cases were initially instigated by Brad, and it was not until yesterday that docker came to me as a natural solution for a little problem I had.
I wanted to test the impact on Camlistore of some specific configuration changes related to HTTPS certificates and domain names, and see if all browsers were ok with it. This is not the kind of thing I can test offhand on my dev machine at home, because I have no domain name pointing to there, and hence no valid (i.e. not self-signed) HTTPS cert either.
What I do have though, is access to a remote server under a domain name, which also happens to have a valid HTTPS cert. However, this server runs a "production" Camlistore server that I do not want to disrupt. One option is of course to carefully craft a Camlistore configuration file, in a non-default directory set by an env var, with a different configuration for where to store the blobs, on which port to run, etc. But maybe I was lazy, and it sounded like an annoying thing to do. And that's where docker comes in. All I had to do was:
mkdir -p tmp/.config/camlistore docker run -v $HOME/tmp/.config/camlistore:/.config/camlistore -p 3180:3179 camlistore/camlistored
The -v option allows me to persist all the configuration stuff from Camlistore in the container (in /.config/camlistore on the container) on the host filesystem (in $HOME/tmp/.config/camlistore). That way I can play around with the configuration file left in there in between runs. The -p option is obviously to map the port Camlistore uses by default in the container (3179) to the 3180 port on the host (because the default port is already used by the production instance).
So yeah, docker is nice. Kindof like a virtual machine, but way easier to set up, and without all the overhead.
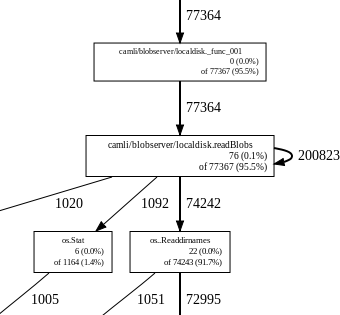
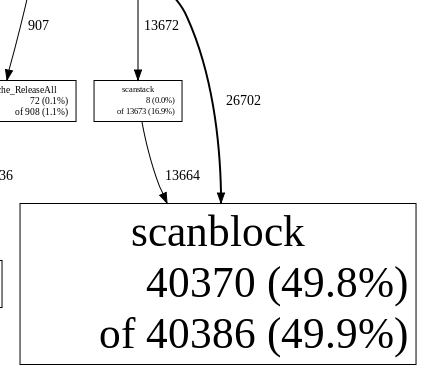
A bit of cpu usage monitoring and Go profiling
It bet it happened to any programmer that at some point he notices that a running program seems to be acting up while it shouldn't. For example you notice the cpu fan starting to go a bit faster, or maybe some disk scratching while you can't think of anything running that would cause this kind of activity.
I recently came accross such a situation; the laptop seemed a bit noisier than usual, and there was some disk i/o happening every dozen seconds or so. The first thing one does is to have a quick look in top. And sure enough the program in question (camlistore, to name it) seemed to be peaking every few seconds at ~90% cpu or so. (To be honest, I was kind of expecting it since I had a recollection of noticing such a behaviour while this program was running).
Now that was the perfect occasion to try gopprof (a script around prof), as I had heard good things about it, but never had an excuse to try it out for a real problem. The Go team wrote a brilliant post about it here, so that's how I got started. Of course, camlistore being a collection of servers, it's not supposed to terminate, so I had to adapt the blog example a bit since one is supposed to flush the measurements right before the monitored program terminates. I could have modified camlistored so that it would capture the termination signal and flush before actually terminating, but I instead went for the easier solution which was simply to program it to terminate after a given duration. Here's the gist of it:
func main() {
flag.Parse()
var f *os.File
var err error
if *cpuprofile != "" {
f, err = os.Create(*cpuprofile)
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
}
/* actual code starts here */
// the last statement was ws.Serve(), which is essentially similar to an
// http server. Since I want to add other statements to be executed while
// the server is running, I got it to run in a goroutine instead.
// Thus it becomes:
// go ws.Serve()
/* actual code ends here */
if *cpuprofile != "" {
log.Print("Before sleeping")
time.Sleep(1800e9)
pprof.StopCPUProfile()
log.Print("pprof stopped")
f.Close()
log.Fatal("camlistore terminated")
}
}
As explained in the blog post, one then has to run the program with -cpuprofile=output.prof, and next run goprof to analyse the measurements produced with the run, like this:
'gopprof path_to_program output.prof'.
One can then use the 'web' command to produce a nice calls graph, from which these two were extracted:



{kind=link}